 saravana kumar
saravana kumar580 California St., Suite 400
San Francisco, CA, 94104
…
9 pages
The International Review on Computers and Software (IRECOS) is a publication of the Praise Worthy Prize S.r.l.. The Review is published monthly, appearing on the last day of every month.
AI






Multiplication is major concern in computations like signal processing, audio video applications. Performing multiplication on Fixed and floating point data is a more time consuming action and necessitates huge quantity of giving out time. By civilizing the speed of multiplication job overall speed of the system can be boosted. The Holdup in the floating point multiplication procedure is the multiplication of mantissas which wants 53*53 bit integer multiplier aimed at double precision floating point numbers, Vedic and Canonic Signed digit set of rules exists to associated parameters like speed, complication of routing, pipelining, source required on FPGA. The comparison showed that Signed Digit Algorithm and Booth Multiplication Algorithm is better than Vedic algorithm in terms of speed and capitals required on spartan3 FPGA.
IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2011
A novel approach of designing serial-serial hybrid multiplier is proposed for applications with high data sampling rate (4 GHz). The conventional way of partial product formation is revamped. Our proposed technique effectively forms the entire partial product matrix in just sampling cycles for an multiplication instead of at least 2 cycles in the conventional serial-serial multipliers. It achieves a high bit sampling rate by replacing conventional full adders and 5:3 counters with asynchronous 1's counters so that the critical path is limited to only an AND gate and a D flip-flop (DFF). The use of 1's counter to column compress the partial products preliminarily reduces the height of the partial product matrix from to log 2 + 1, resulting in a significant complexity reduction of the resultant adder tree. The proposed hybrid column compressed multiplier consists of a serial-serial data accumulation unit and a parallel carry save adder (CSA) array that occupies approximately 35% and 58% less silicon area than the full CSA array multiplier with operands of wordlength 32 32 and 64 64, respectively. The post-layout simulation results based on 90-nm seven metal single poly CMOS process technology shows that our 64 64 multiplier dissipates 39% less average power at a sampling rate of 4 GHz, and has only 11% additional delay penalty to complete a multiplication compared to the conventional fully parallel CSA array multiplier. Index Terms-Binary multiplication, on-chip serial-link bus architecture, on-the-fly accumulation, parallel multipliers, serial-serial and serial-parallel multiplier.
Terms of both latency and power Digit-serial implementation styles are best suited for implementation of digital signal processing systems which require moderate sampling rates. Digit-serial architectures obtain using traditional unfolding techniques cannot be pipelined beyond a certain level because of the presence of feedback loops. In this paper, an alternative approach for the design of digit-serial architectures is presented based on a novel design methodology. This methodology permits bit-level pipelining of the digit-serial architectures by moving all feedback loops to the last stage of the design. This enables bit-level pipelining of digit-serial architectures, thereby achieving sample speeds close to corresponding bit-parallel multipliers with lower area. This increased sample speed can be traded with reduction in power supply voltage resulting in significant reduction in power consumption. The proposed approach is applied to the design of various multipliers which form the backbone of digital signal processing computations. The results show that for transformed multipliers with smaller digit sizes (_4), the singly-redundant multiplier consumes the least power, and for larger digit sizes, the type-I multiplier consumes the least power. It is also found that the optimum digit size for least power consumption in type-I and type-III multipliers is _p2W, where W represents the word length. Among the bit-level pipelined digit-serial multipliers, it is found that the redundant multiplier offers the best choice in consumption The proposed digit-serial multipliers consume on average 20% lower power than the traditional digit-serial architectures for the non pipelined case and about 5–15 times lower power for the bit-level pipelined case.
In the field of embedded electronics the information of circuits (processors and other integrated circuits) is vital. In order for such connection to be established a common protocol must be assigned to them one of such is the serial communication protocol. Serial communication is common method of transmitting data between a computer and a peripheral device such as a programmable instrument or even another computer. Serial communication transmits data one bit at a time, sequentially, over a single communication line to a receiver. Serial is also a most popular communication protocol that is used by many devices for instrumentation; Numerous devices also come with an RS232 based port that is based on this protocol. However, because of the rapid evolution of this protocol its counter part the parallel communication protocol is not commonly used because the standards that are available with serial communication can easily achieve the original purpose of a parallel communication protocol which is primarily a high relative throughput. Arduino is an open-source platform used for building electronics projects. Arduino consists of both a physical programmable circuit board (often referred to as a microcontroller) and a piece of software, or IDE (Integrated Development Environment) that runs on your computer, used to write and upload computer code to the physical board. This paper has the aim to look at serial communication and how Arduino utilizes such protocol in creating complex and vital embedded electronics. This paper will achieve this by giving and overview on Arduino, serial communication and then briefly explain how Arduino utilises such feature.
Electronics Letters, 1998
IEEE Communications Magazine, 2001
The architecture and critical circuit design issues for high-speed serial data links operating in excess of 1 Gb/s are described. Trade-offs in power vs. performance are presented for SONET/SDH transceivers and backplane transceivers for Infiniband or similar standards.
Proceedings of the Tenth International Conference on Microelectronics (Cat. No.98EX186)
In this paper, a new design of serial-paiallel multipliers based on the Modified Booth algorithm is proposed. The proposed multiplier implementation on a PCI initiztorrnarget Interface Card (where a single chip design, XC4010E, is used to implement fi PCI Local Bus interface, revision 2.1, protocol and timing compliance) is demonsterated. The flexible design of the PCI-interface can be easily adapted for specific interface requirements. This interface card can be used for different DSP applications. The multiplier is compared with one proposed recently in terms of speed and hardware, and is shown to be faster (for large multipliers, it tends to provide double speed), and having a lower area x time complexity. An implementation using a FPGA-based PCI-interface Card have been made for an 8x8 multiplier. The design was tested using simulation software.
2014 International Conference on Signal Processing and Integrated Networks (SPIN), 2014
The paper proposes a systematic design methodology for bit-serial multiplication. The proposed approach is a modified method for performing traditional multiplication. This paper presents a general technique for NxN bit-serial multiplication used in signal processing. HDL implementation and simulation of 4x4 bit-serial multiplier is discussed. Synthesis is performed using Xilinx ISE with Virtex-4 ML402 FPGA board.
Multiplication or repeated addition is the basic operation used in both Mathematics and Science. The speed of multiplier determines the speed of all Digital Signal Processors. This paper describes four multipliers that is Modified Booth Multiplier, Vedic Multiplier (Urdhva Tiryakbhyam Sutra), Wallace Multiplier and Dadda Multiplier. In Modified Booth Multiplier Algorithm ‘0’ is appended to the right of LSB and then three bits starting from the LSB are grouped as a set to decide the partial product. So as to increase its speed, desk calculators are used that perform the operation of shifting faster. Urdhva Tiryakbhyam Sutra is performed by two multiplication techniques that is straight above multiplication and diagonal multiplication. Then finally, their sum is taken. Here reduction of multi bit multiplication to single bit multiplication takes place followed by the process of addition. Since there is only one step generation of partial product, carry propagation from LSB to MSB is reduced. There are three steps in which both Wallace and Dadda Multiplier work. They are partial product formation, reduction of partial products formed to two rows and addition of these two rows using carry propagation adder. Wallace Multiplier reduces all possible partial products and so has a smaller carry propagating adder whereas Dadda Multiplier performs only minimum necessary reduction and thus has a larger carry propagating adder. But as far as speed is concerned Dadda Multiplier is faster than Wallace Multiplier. Keywords- Modified Booth Multiplier, Vedic Multiplier, Wallace Multiplier, Dadda Multiplier, partial products.
International Journal of Emerging Trends in Engineering Research, 2023
The I/O (Input Output) module conveys the information between I/O device and processor. I/O devices are majorly of two types: Parallel I/O and Serial I/O. Parallel I/O performs multiple I/O operations simultaneously. Due to this speed and higher bandwidths are achieved, but the usage of parallel I/O devices is decreasing as time progresses because it involves complex design due to the usage of multiple wires for the transmission hence only limited to usage in shorter distances. It also uses a greater number of pins compared to serial I/O for the same number of data bits which makes its usage problematic in higher level devices. Serial I/O transmits individual data bits sequentially. It uses lesser number of lines for data transmission thereby reducing the design complexity. Since, the data transmission is sequential the signal delay increases. Thus, this project aims to develop a protocol which achieves High Speed Serial I/O which helps to increase the data rate from Mbps to Gbps, decrease the design complexity, to design hardware using fewer number of pins on PCB and reduce signal delay to maximum extent possible.
AI
The HS-SS multiplier shows a delay reduction compared to Lyon's, conventional, Kanapaulous, and Meher designs, achieving up to 21.1% area reduction and 13.6% power savings.
It uses a Cycle Tracker for term generation, producing 2n+1 terms per cycle, minimizing the number of gates required for partial products.
The design employs Dadda's methodology for partial product reduction, and operates on both clock edges to enhance speed.
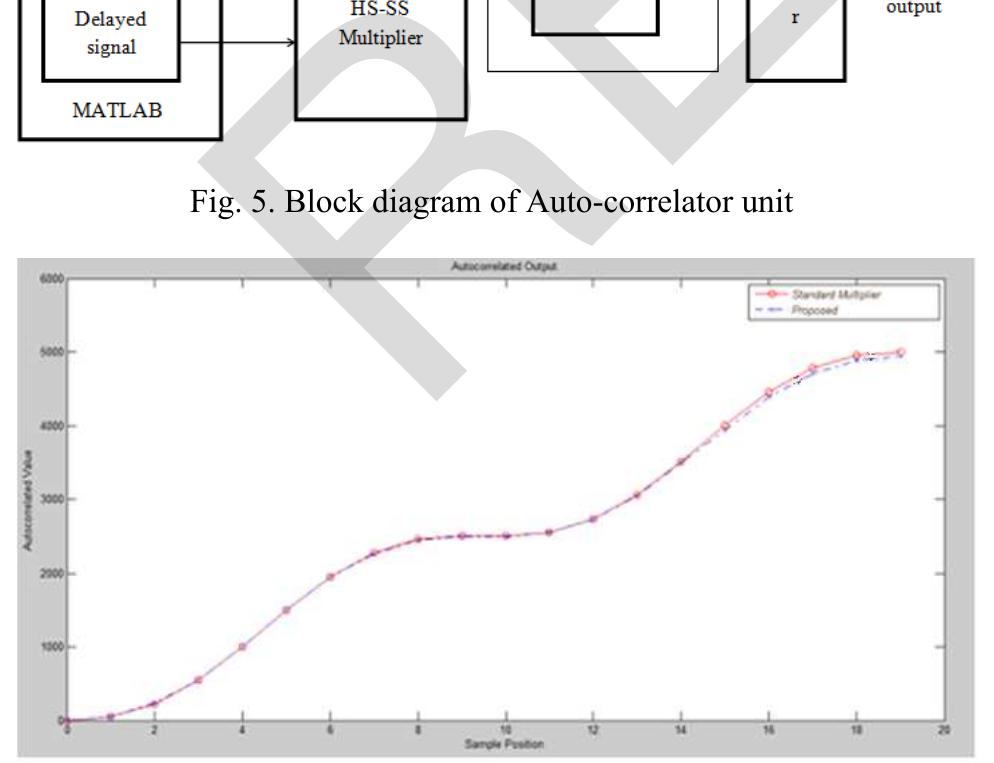
The proposed multiplier is verified within an auto-correlator unit for Orthogonal Frequency Division Multiplexing, showcasing its applicability in DSP tasks.
By employing pipelining and parallel processing of inputs, the multiplier outputs one bit of the result per clock cycle, thus enhancing overall throughput.
Najini Noorbhasha & P. Ramakrishna, 2013
In the past few years, multipliers have been a tremendous increase in the demand for better quality electronic equipment because of increasing standards of living of people. This has led to the development of new technologies like System On Chip (S.O.C)s and scaling down the transistor sizes so that we can integrate a greater amount of functionality into a smaller area of silicon. The densely packed components will result in higher power consumption per unit area of silicon and higher power dissipation too. This could result in increasing the temperature of the chip which could slow down the chip or could damage it. The higher power consumption also leads to quick draining of battery operated devices. In many palm-hold devices like smart phones, i-pods etc there are many applications like voice interface, high definition audio and video, video calling, 3G and 4G services, etc. which needs a very good quality DSP circuit.FIR Filters are a major component of DSP circuits. FIR Filters mainly comprise of multipliers and adders as the power consuming elements. For a good quality DSP circuit we need to implement an FIR Filter with wide multipliers that give good precision and range for good multiplication. And also some times to reduce the wiring cost, it is common practice to transmit the data through a high speed serial link. In some ICs the designers try to reduce the number of IO pads in order to reduce the power consumption and silicon area. Therefore efforts are made to design high speed serial interface in order to facilitate on-chip buffering and parallel processing. In this project we design seral-serial multiplier to reduce the complexity of SOC‟s, and power dissipation. The RTL coding for this project has been done in verilog HDL. Modelsim Simulator has been used to perform functional verification through simulation. XILINX ISE is used to perform synthesis and power analysis.
A new bit serial-serial multiplier for unsigned numbers is presented in this paper. The numbers being multiplied enter the circuit simultaneously in LSB first bit-serial form. The multiplier is of immediate response, pipelined at the bit level and has small combinational delay. A variation of this multi- plier that operates with 100% efficiency, namely it does not require zero bits to be inserted between successive input data words, produces the product in full-precision is also proposed. The proposed schemes are well suited for DSP applications, compared with other schemes exhibit superior performance in terms of hardware complexity and through- put.
Solid-State Circuits, IEEE Journal of, 1989
Of the serial multipliers documented in the literature, those based upon the modified Booth algorithm dominate in applications where reduced latency and area are required. The modified Booth method com putes redundant-radix-4 partial products by multiplying the multiplicand by 0, ± I, or ± 2 in each stage. Interpreting multiplier data in terms of radices other than binary or redundant-radix-4 has been rejected in the past using the rationale that each stage would become unduly complex and counte .... lct gains otherwise obtained from the reduced number of stages. This paper describes a serial multiplier based upon a new mapping of a nonredundant·radix·4 multiplication algorithm. This multiplier forms bi nary partial products by adding multiples of 0,1,2, or 3 times the multipli cand in all internal modules. The circuit described uses simpler recOIling circuitry while retaining the same order area and time of the modified Booth multiplier.
IEE Proceedings - Circuits, Devices and Systems, 2004
All serial-serial multiplication structures reported in the literature has been confined to bit serial-serial multipliers. In this paper, an architecture for digit serial-serial multipliers is presented. A set of designs are derived from the radix-2 n design procedure which was first reported by the authors for the design of bit level pipelined digit serial-parallel structures [8]. One significant aspect of the new designs is that they can be pipelined to the bit level and give the designer the flexibility to obtain the best trade off between throughput rate and hardware cost by varying the digit size and the number of pipelining levels. Also in this paper an area efficient digit serial-serial multiplier is proposed which provides a 50% reduction in hardware without degrading the speed performance. This is achieved by exploiting the fact that some cells are idle for most of the multiplication operation. In the new design, the computations of these cells are re-mapped to other cells, which make them redundant. The new designs have been implemented on the S40BG256 device from the SPARTAN family to prove functionality and assess performance.
ijircce, 2015
In this paper Design of high speed MAC unit based on Vedic multiplier algorithm. Generally MAC useful application such as Digital signal processing like FFT transform , Convolution and correlation. MAC is hardware based module therefore first design of multiplier block and second one is adder block. in this paper to implementation 64bit MAC with reduce the delay and increase the speed of system. The coding done by verilog-HDL and its synthesis and simulation on XILINX ISE.14.5 tool.
This paper describes basics methods of transferring data through serial data buses, using serializer/deserializer (SerDes) as main device in this operation. It explains function of SerDes and different techniques for implementing it.
2000 IEEE International Symposium on Circuits and Systems. Emerging Technologies for the 21st Century. Proceedings (IEEE Cat No.00CH36353), 2000
A new bi-directional bit serial-parallel multiplication architecture is presented. The proposed structure is regular and modular, and requires nearest neighbour communication links only, which makes it more efficient for VLSI implementation. Furthermore, a judicious deployment of larches in the circuit ensures that the multiplier operates on two coefficients of the multiplicand at the same time thus speeding up the process. Comparison of the new multiplier structure with previous ones has shown the superiority of the new architecture.
Journal of Systems Architecture, 1998
We propose a novel architecture of an asynchronous bit-serial multiplier with counterflow data streams. The crucial idea of the proposed design is that data transfer between basic cells is acknowledged by another data transfer in the opposite direction. This design solution has resulted in lower hardware complexity because there is no extra acknowledged circuitry. For the multiplier design, a mixed-mode delay model is adopted. First, the control circuit of the multiplier's basic cell is designed as a speed-independent circuit. Then the method for interconnecting basic cells into a 1D array is presented. Finally, we incorporate data-path function into the basic cell under the bounded-delay model.
This Paper presents an efficient implementation of high speed multiplier using the shift and add method, Radix_2, Radix_4 modified Booth multiplier algorithm. In This paper we compare the working of the three multipliers by implementing each of them separately in FIR filter. The parallel multipliers like radix2 and radix4 modified booth multiplier does the computations using lesser adders and lesser iterative steps. As a result of which they occupy less space as compared to the serial multiplier. This a very important criteria because in the fabrication of chips and high performance systems requires components which are as small as possible. Low power consumption and smaller area are the most important criteria for the fabrication of DSP systems and high performance systems. Optimizing the speed and area of the multiplier is a major design issue. However, area and speed are usually conflicting constraints improving speed results mostly in larger areas. This is to determine the best solution to this problem by comparing a few multipliers. The paper gives the analysis of comparison of power consumption of all the multipliers & we find that serial multipliers consume more power. So where power is an important criteria parallel multipliers like booth multipliers are preferred to serial multipliers.
2008 3rd International Design and Test Workshop, 2008
A new high precision serial multiplier with Most Significant Digit First (MSDF) is presented. This one uses a Borrow-Save (BS) adder to perform the reduction of large length partials products required by the multiplication of large numbers. The results are converted from BS form to the 2's complement representation by the on-the-fly conversion which let the conversion of the digit result as soon as it is obtained. It is shown that the comparison between the residual and these constants (-3/2,-1/2, 1/2 and 3/2) needed in the radix-2 on line multiplication, present problem in high precision computation. However, in the proposed method the operands are introduced digit by digit with MSDF mode and results are obtained in the same manner with fixed time delay independently of the operand size. So, this approach is advantageously used for the long multiplication computation. This method has been tested by the execution of a program developed with Maple 9.5 for several test vectors. The results of the implementation of this multiplier for several operands sizes (128,256, 512, and 1024) on Virtex-II FPGA Circuit confirm that the multiplication is performed in constant time.