








580 California St., Suite 400
San Francisco, CA, 94104
This research area focuses on refining information leakage metrics to better capture privacy risks when adversaries do not possess complete statistical information about the data and mechanisms. Traditional metrics assume full knowledge of data distributions, an assumption that often fails in practical scenarios. Addressing this gap is crucial for designing privacy-utility trade-offs and optimal disclosure mechanisms under realistic adversarial uncertainty.
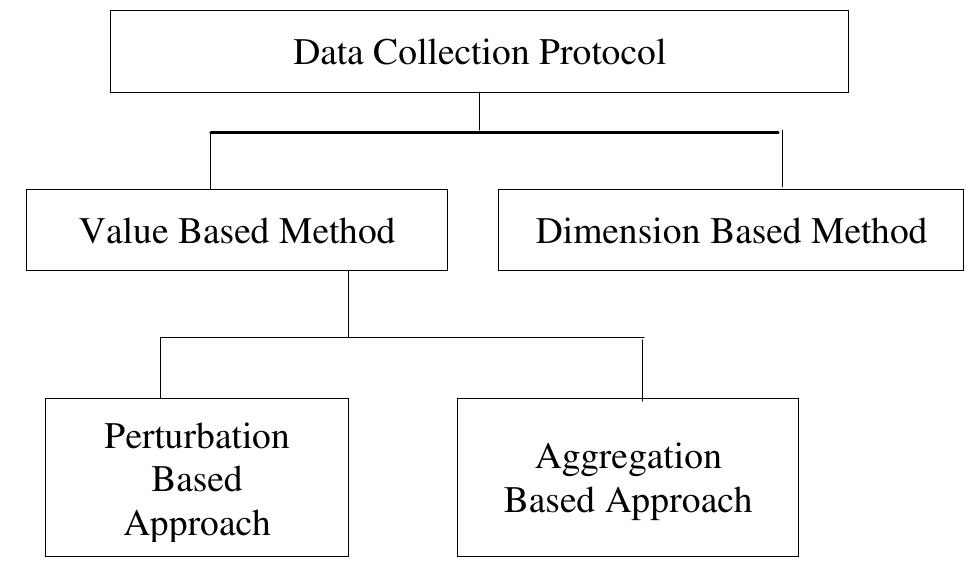
This theme examines the challenges and methodologies in implementing differential privacy (DP) and similar noise-injection mechanisms in official statistical releases. It focuses on balancing rigorous privacy protections against the utility of statistical outputs, especially in the context of sensitive, high-dimensional population and employer-employee datasets. Issues such as noise distribution choice, bounded vs. unbounded noise, and output complexity effects on privacy-utility trade-offs are investigated.
This theme investigates techniques for generating privacy-preserving synthetic datasets and their impact on downstream analytical tasks, including machine learning classification and inference on covariance structures. It covers evaluation of synthetic data generators, the role of anonymization (e.g., microaggregation enhanced by linear discriminant analysis), and statistical procedures adapted for synthetic datasets, balancing confidentiality protection with preserving empirical data utility.